

Wer einen Computer besitzt, hat vermutlich auch schonmal ein Bild, ein Dokument oder eine Musikdatei gespeichert. Dabei greift der Rechner traditionell auf irgendwelche Festplatten zurück, die im selben Gehäuse verbaut sind, also praktisch auf internen Speicher.
Mit Servern ist das grundsätzlich nicht anders, diese haben im Zweifel sogar sehr viele Festplatten zur Auswahl, da sie potentiell für Anwendungen verwendet werden, die einen hohen Speicherbedarf haben. Je mehr Server ich nun habe, desto unpraktischer ist das allerdings. Zum einen muss ich das Speichersystem für jeden Server separat verwalten, zum anderen kann dabei schnell eine ziemlich ineffiziente Ressourcenausnutzung entstehen. Wenn ich bspw. zehn Server betreibe, bei denen jeweils die Hälfte des Speichers belegt ist, dann habe ich theoretisch ungenutzten Speicherplatz für zehn weitere Maschinen. Und seien es zwecks „Luft nach oben“ nur fünf, ich hab ein jedem Fall für etwas bezahlt, was ich gar nicht brauche. Hinzu kommen möglicherweise der Bedarf für zentrale Datenhaltung (anstatt eine Kopie auf jedem Server vorzuhalten) und zig weitere Anforderungen, in jedem Fall gibt es Bedarf für externe Datenhaltung.
An dieser Stelle kommt das Storage Area Network (SAN) ins Spiel. Dabei wird im Grunde genommen das interne Kabel oder Bussystem, das auch im kleinsten PC zwischen CPU und Speicher sitzt, durch ein Netzwerk ersetzt und der Speicher (oder ein Teil davon) wird in ein (oder mehrere) externes Storage-Array ausgelagert.
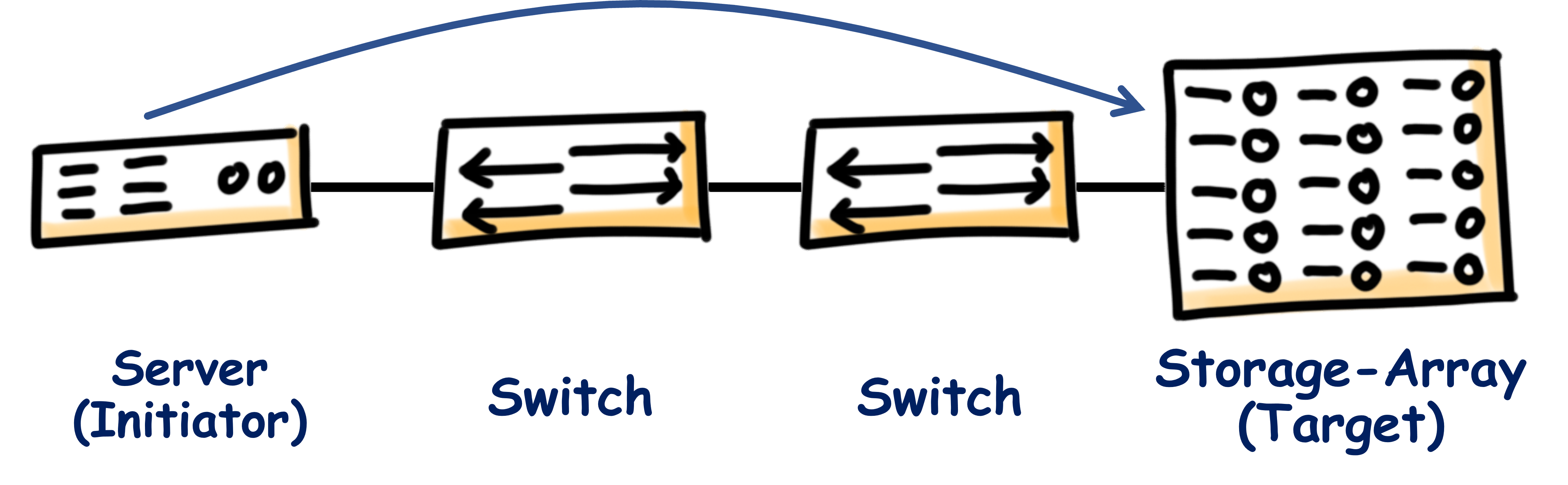
Auf diese Weise kann der Speicher für alle Server zentralisiert bereitgestellt werden. Die Daten können redundant vorgehalten werden, ohne dass einzelne Server dafür konfiguriert werden müssen, kaputte Platten können an einer Stelle ausgetauscht werden usw. usf.
Dabei stellen die Storage-Arrays im SAN Block-Level-Storage bereit. Das bedeutet einfach ausgedrückt (und komplizierter verstehe ich es auch selbst nicht), dass dem Betriebssystem der Server die Festplatten so präsentiert werden, als wären sie intern verbaut. Dabei können die Festplatten tatsächliche physisch vorhandene Disks im Array sein, aber auch logische Konstrukte, die nur den Teil einer Festplatte oder gleich mehrere Disks umfassen. Für das Betriebssystem des Servers ist es egal, er erhält schlicht und ergreifend eine Festplatte, die es addressieren und nutzen kann. Das Gegenstück dazu ist im Übrigen der File-Level-Storage, wie man ihn bspw. von einem Network Attached Storage (NAS) bekommt. Die wird dann im Windows-Explorer zwar auch als Festplatte angezeigt, allerdings als Netzlaufwerk. Dem Betriebssystem ist also in diesem Fall durchaus bewusst, dass die Platte nicht lokal vorhanden ist.
Nun gibt es für den Server allerdings ein Problem. Das Betriebssystem weiß nicht, dass der Storage nicht lokal erreichbar ist, nutzt also dieselben Lese- und Schreiboperationen, wie bei einer internen Festplatte. Diese müssen in irgendeiner sinnvollen Form ans Netzwerk übergeben, über selbiges übertragen und am Storage-Array verarbeitet werden. Dafür gibt es verschiedene Protokolle, mit denen ich mich in weiteren Beiträgen auseinandersetzen möchte. Allen ist gemein, dass sie die orginalen unveränderten Operationen des Betriebssystems als Nutzlast übertragen und dadurch erst die Transparenz ermöglichen, mit der Block-Level-Storage über ein SAN bereitgestellt werden kann. Im Rahmen der Protokolle übernimmt der Server die Rolle des sogenannten „Initiator“ (Englisch, daher ohne Genitiv-„s“), während der Storage-Array zum „Target“ wird. Aber wie gesagt, dazu an anderer Stelle mehr.
Antworten